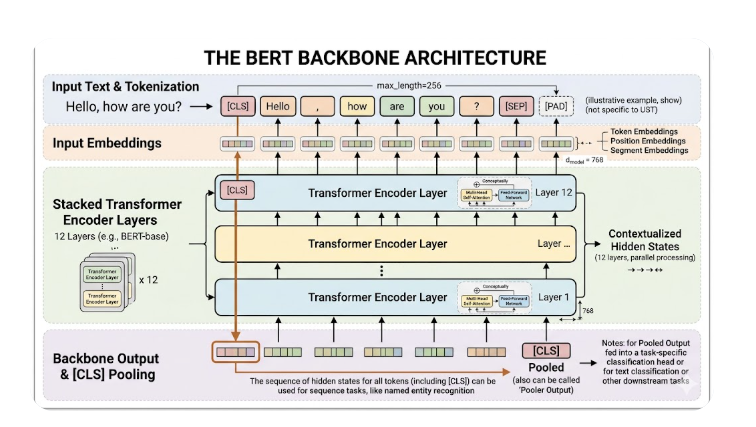
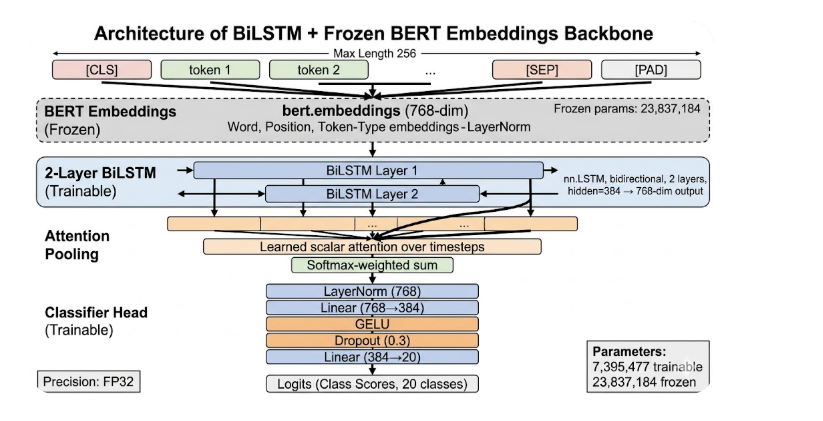
- Embedding: full BERT embedding module (
bert.embeddings) — 768-dim, completely frozen
- Frozen params: 23,837,184 (word + position + token-type embeddings + LayerNorm)
- Recurrent layer: 2-layer bidirectional
nn.LSTM, hidden=384 → 768-dim output
- Variable-length input:
pack_padded_sequence respects attention mask
- Attention pooling: learned scalar attention over LSTM timesteps → softmax-weighted sum
- Classifier: LayerNorm → Linear(768→384) → GELU → Dropout(0.3) → Linear(384→20)
- AMP off — BERT LayerNorm uses eps=1e-12 (too small for FP16); trained in FP32
7,395,477 trainable · 23,837,184 frozen