Regularisation Strategy
- Dropout (0.3): applied in BiLSTM embedding, between LSTM layers, and in both classifiers.
- Weight decay (1e-2): L2 penalty via AdamW; for BERT, bias and LayerNorm params are excluded (weight_decay=0.0 group).
- Label smoothing (0.1 for BERT, 0.05 for Ensemble): prevents overconfidence; not used for BiLSTM (standard CE).
- Gradient clip (max_norm=1.0): applied before every optimizer step for both BERT and BiLSTM.
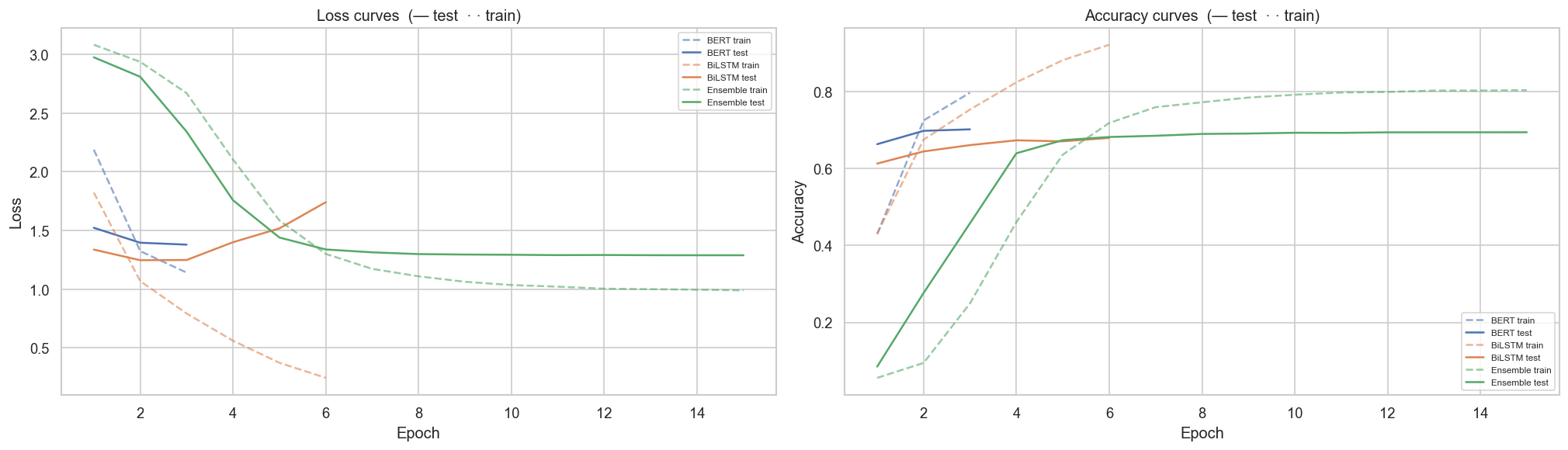
- Early stopping: patience 3 (BERT) and 4 (BiLSTM) — best checkpoint persisted to disk.