Key Findings
- BERT wins convincingly at 70.23% — a +2.23% gap over BiLSTM, demonstrating the power of fine-tuning the full pre-trained Transformer versus using frozen embeddings alone.
- Ensemble falls between both (69.48%): the meta-MLP improves over BiLSTM (+1.48%) but cannot fully match BERT due to the BiLSTM's lower individual ceiling.
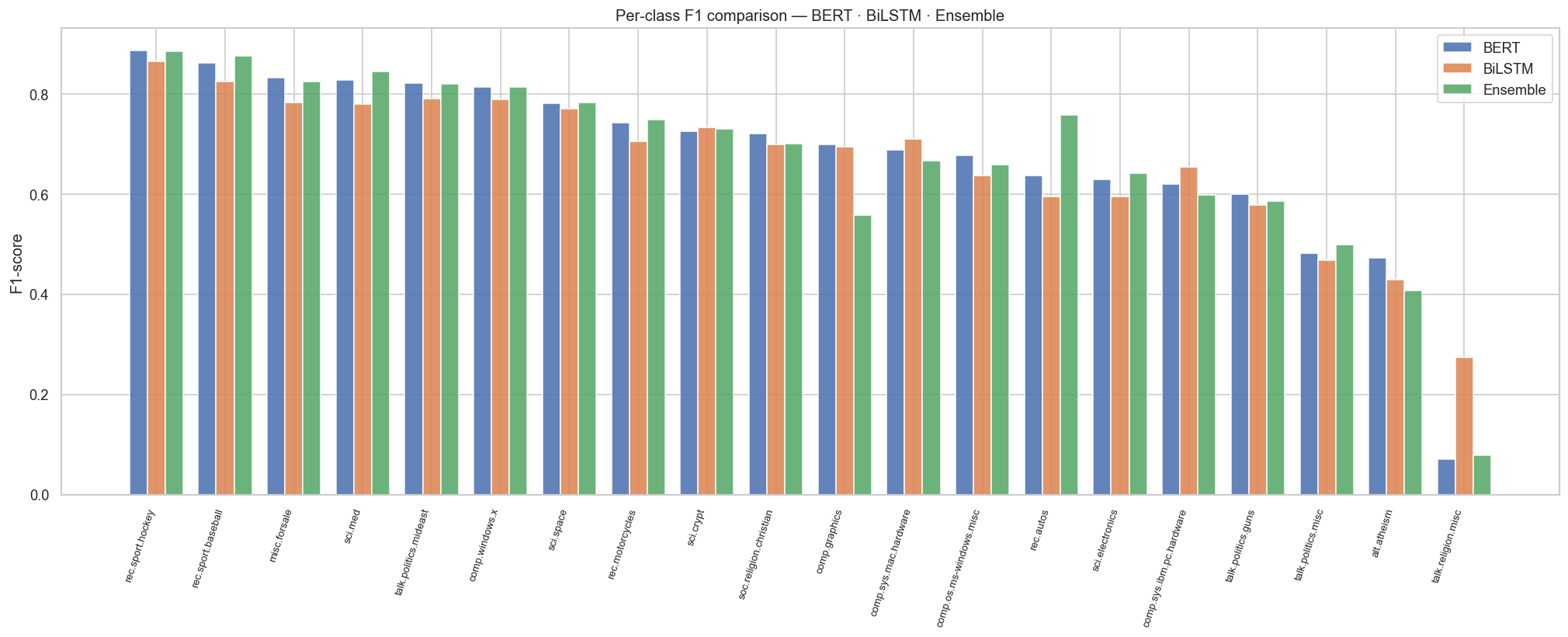
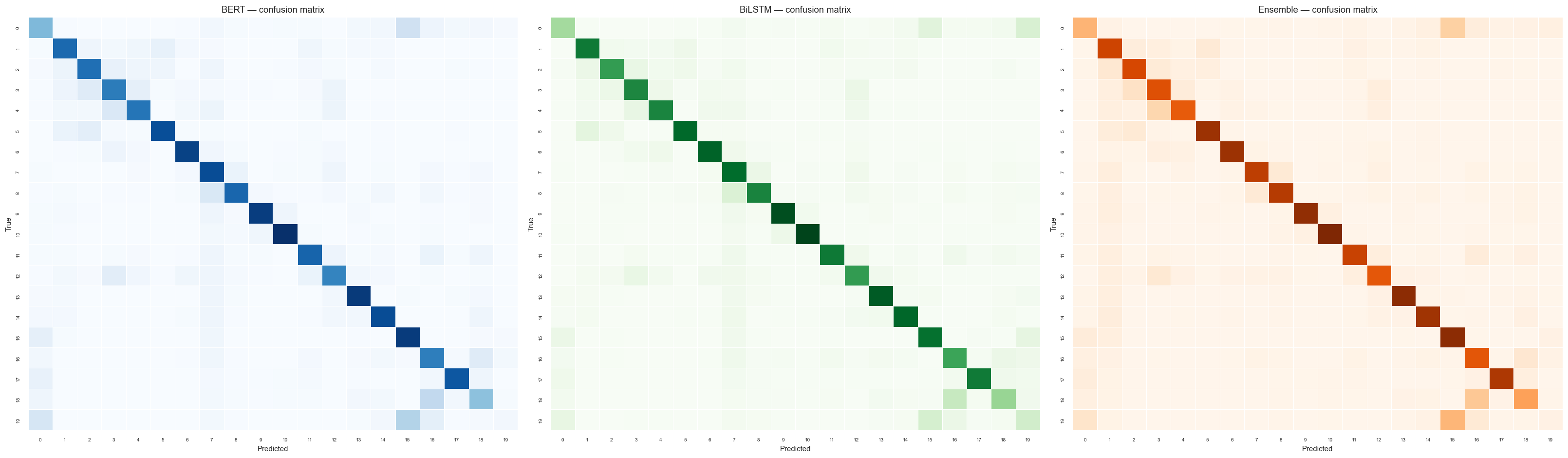
- Hardest classes: talk.religion.misc (BERT F1=0.07 — severe overlap with alt.atheism and soc.religion.christian) and alt.atheism across all models.
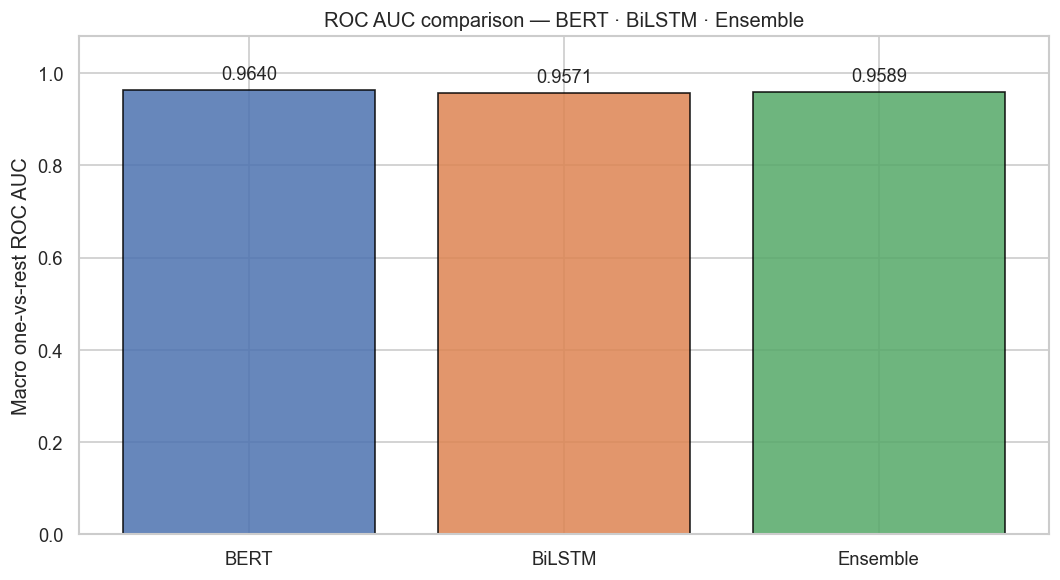
- All models exceed ROC AUC 0.957 — probability calibration is strong even in hard classes.
- BiLSTM's AMP-off (FP32) training prevents LayerNorm NaN issues but slows per-epoch speed vs BERT's AMP+grad-accum setup.