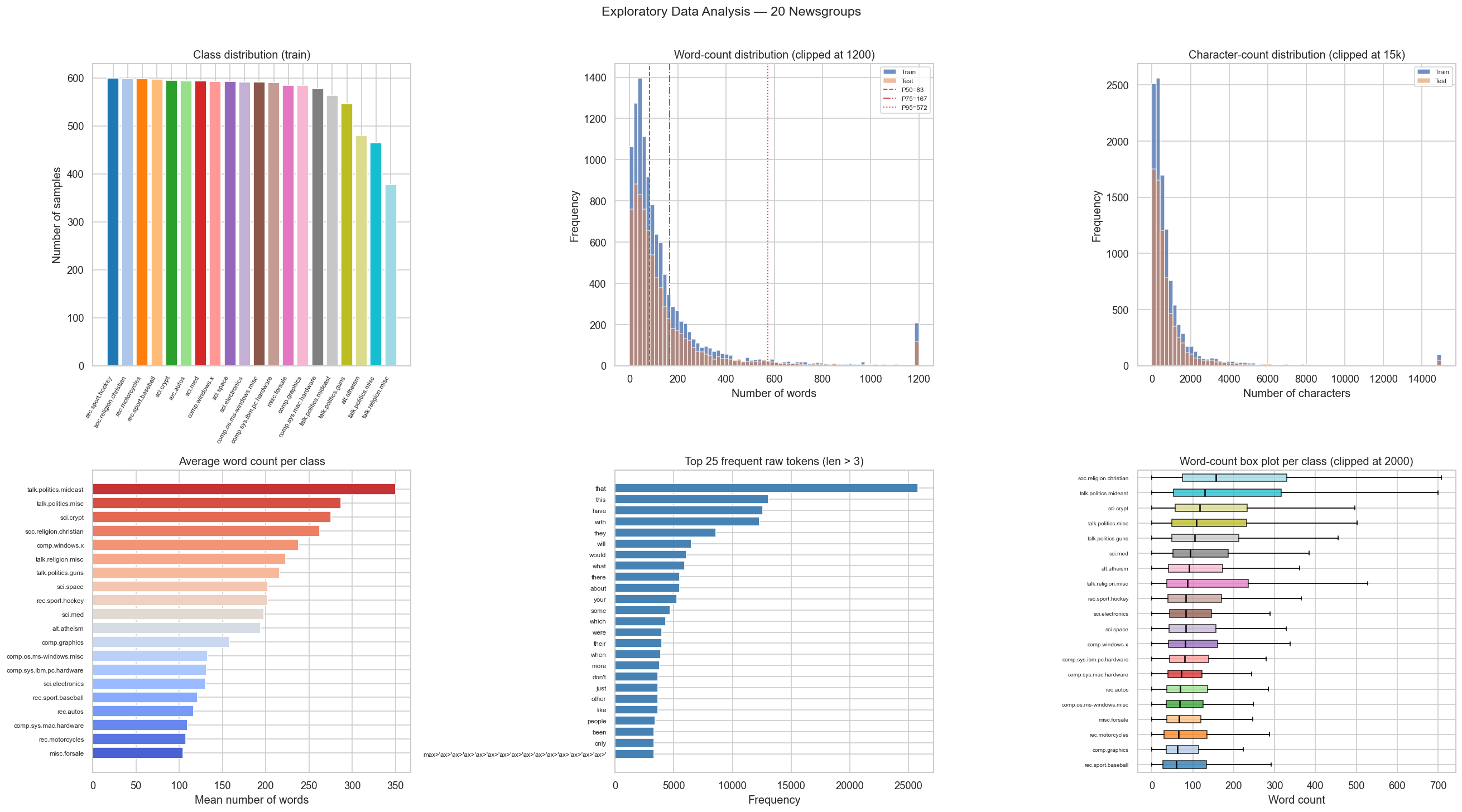
Primary Findings
- Near-balanced classes: each topic holds ≈480–600 training samples — no oversampling needed.
- Heavy length tail: max post is 11,765 words; median is 83. A 256-token BERT cap safely covers the majority while staying within 6 GB VRAM.
- Empty texts: 218 train / 162 test samples are entirely empty after loading — passed as empty strings to the tokenizer (→ [CLS][SEP][PAD…]).
- Raw text requires no custom preprocessing beyond what BERT's WordPiece tokenizer handles — lowercasing is implicit in
bert-base-uncased.